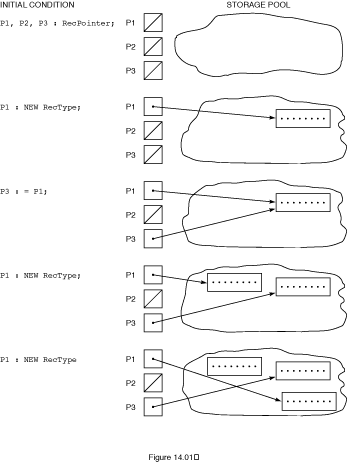
You know how to use arrays to store collections of data. You also know that it is possible for each array element to be a record and have seen a number of examples of such data structures. One characteristic of data collections is that they can vary in size considerably from one run of a program to the next or even during a run. In such cases, an array is not the best structure in which to store the records, because the array size is fixed and therefore must be estimated before the records are read in. If only a few records are present, much space is wasted. Worse, the array cannot expand to hold a number of records greater than its size.
There is a solution to this problem, called dynamic data structures or linked data structures. Using dynamic data structures, the programmer can increase or decrease the allocated storage in order to add or delete data items in the collection. In languages like Ada that provide built-in support for linked structures, the compiler associates with an executable program a special storage area, called the dynamic storage pool, or sometimes just pool, which it initially leaves unassigned to any program variable. A system module called the storage allocator is linked into the program and assumes responsibility for allocating blocks of storage from the pool, and returning extra blocks to the pool, at execution time. The pool is like a "storage account" from which a program can "borrow" storage to expand a structure, returning the storage when it is no longer needed. The storage allocator can then use that storage to satisfy another storage request from the program.
A special kind of variable is provided for referencing space allocated dynamically from the pool. In Ada these are called access variables; in other languages, such as Pascal and C, they are referred to as pointer variables. Ada allows us to declare access types, and each access variable is an object of an access type. The values of each access type are called access values, or, informally, pointers. A pointer or access value is an abstraction for a hardware address but often does not have the same form.
Consider a record type called RecType, defined as
TYPE RecType IS RECORD
... fields ...
END RECORD;
The type definition
TYPE RecPointer IS ACCESS RecType;
gives us the ability to declare access variables of type
RecPointer, that is, variables that can designate, or hold
pointers to, things of type RecType. For example, a declaration
P1, P2, P3: RecPointer;
allocates storage for three such variables.
When an access variable is created in Ada, its value is always initialized
to a special, unique internal value known as NULL. This indicates
that the pointer doesn't point to anything (yet). It is important to realize
that declaring such variables does not cause any records to be allocated; each
variable is given just enough space to hold the address of a record.
How do the records themselves come into being? The Ada operator
NEW creates them. An assignment statement such as
P1 := NEW RecType;
causes the storage allocator to search the pool, looking for a
block of space large enough to hold a record of type RecType. When
such a block is found, an access value designating (pointing to) this block is
stored in the variable P1.
Figure
14.1 shows diagrammatically how dynamic allocation works. The cloudlike
shape represents the pool, arrows represent pointers, and diagonal lines
represent NULL.
Figure
14.1
Dynamic Allocation
An access variable can acquire a value in only two ways: A value can be
delivered by a NEW operation, as above, or it can be copied from
another access value. For example,
P3 := P1;
causes P3 to point to the same record to which
P1 points. An assignment statement to an access variable copies
only an access value; it does not copy the designated value!
If we write
P1 := NEW RecType;
a second time, space for another record is found in the pool,
its address is stored in P1, and P3 is left pointing
to the "old" record. If we write
P1 := NEW RecType;
a third time, the record previously pointed to by
P1 is left with nothing pointing to it, thus making it
inaccessible. This space, in general, remains allocated and unavailable
for other use. This situation is often called, picturesquely, a "storage leak,"
because the storage "leaks away" and can no longer be used. We will return to
this subject later in the chapter.
Because we do not know beforehand how many nodes will be needed in a dynamic data structure, we cannot allocate storage for it in the conventional way, that is, through a variable declaration. Instead, we must allocate storage for each individual node as needed and somehow join this node to the rest of the structure.
We can connect two nodes if we include a pointer field in each node. The declarations
TYPE ElectricityType IS (DC, AC);
TYPE Node;
TYPE NodePointer IS ACCESS Node;
TYPE Node IS RECORD
Power : ElectricityType;
Volts : Natural;
Next : NodePointer;
END RECORD;
identify NodePointer as a pointer type. A pointer
variable of type NodePointer points to a record of type
Node with three fields: Power, Volts,
and Next. The Next field is also of type
NodePointer. We can use this field to point to the next node in a
dynamic data structure.
Note that the first declaration of Node is incomplete;
it just mentions the name Node without filling in the details.
This device is used to inform the compiler of the existence of the type
Node so that the next type definition can use it. Using an
incomplete type definition meets Ada's requirement that types must be defined
before they can be used.
Now let us declare some pointer variables:
P : NodePointer;
Q : NodePointer;
R : NodePointer;
As in the previous example, P, Q, and
R are automatically given initial NULL values. The
assignment statements
P := NEW Node;
Q := NEW Node;
allocate storage for two records of type Node,
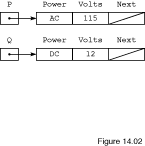
storing their addresses in P and Q. Initially the
Power and Volts fields of these records are
undefined; the Next fields of both are initially
NULL. Pointer initialization is one of the few cases in Ada where
objects are given initial values at declaration.
In Ada terminology, a nonnull access object designates a value. The
block of space pointed to by P is P's designated
value. We can refer to the designated value of P using the
expression P.ALL, and to the Power field of
P.ALL by the expression P.ALL.Power. The assignment
statements
P.ALL.Power := AC;
P.ALL.Volts := 115;
Q.ALL.Power := DC;
Q.ALL.Volts := 12;
define the nonlink fields of these nodes, as shown in
Figure
14.2. The Next fields are still NULL.
Figure
14.2
Nodes P.ALL and Q.ALL
The .ALL construct is the way Ada represents a
dereferencing operation, that is, an operation to find that value to
which a pointer points. To simplify the syntax necessary to select a field of a
designated value, Ada allows us to omit the .ALL part and just
select the field directly. Therefore, the following four assignment statements
are equivalent to the ones just given: We will use the abbreviated form
throughout this chapter. Because P is an access variable, we can
read the expression P.Power as "find the value designated by
P and select its Power field."
P.Power := AC;
P.Volts := 115;
Q.Power := DC;
Q.Volts := 12;
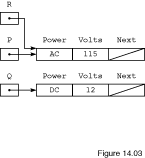
Let us do some more pointer manipulation. The assignment statement
R := P;
copies the value of pointer variable P into
pointer variable R. This means that pointers P and
R contain the same access value and, therefore, point to the same
node, as shown in
Figure
14.3. Here and in later figures we have left out the cloud symbol for
simplicity.
Figure
14.3
Nodes R.ALL/P.ALL and Q.ALL
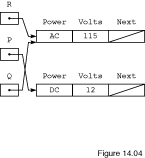
The pointer assignment statements
P := Q;
Q := R;
have the effect of exchanging the nodes pointed to by
P and Q, as shown in
Figure
14.4.
Figure
14.4
Nodes R.ALL/Q.ALL and P.ALL
The statements
Electricity_IO.Put(Item => Q.Power, Width => 4);
Electricity_IO.Put(Item => P.Power, Width => 4);
display the Power fields of the records designated
by Q and P. For the situation depicted in
Figure
14.4, the line
AC DC
would be displayed. (As usual, Electricity_IO is
an instance of Enumeration_IO.)
The statement
Q := NEW Node;
changes the value of Q to designate a new node,
thereby disconnecting Q from its previous node. The new values of
pointer variables P, Q, and R are shown
in
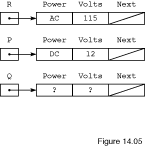
Figure
14.5. The data fields of the new node designated by Q are, of
course, initially undefined.
Figure
14.5
Nodes R.ALL, P.ALL and Q.ALL
It is important to understand the difference between P and
P's designated value. P is an access variable (type
NodePointer) and is used to store the address of a data structure
of type Node. P can be assigned a new value either by
calling NEW or by copying another access value of the same type.
P.ALL is the name of the record designated by P and
can be manipulated like any other Ada record. The field selectors
P.Power and P.Volts may be used to reference data (in
this case, an enumeration value and an integer) stored in this record.
Connecting Nodes
One purpose of introducing dynamically allocated nodes is to be able
to grow data structures of varying size. We can accomplish this by connecting
individual nodes. If we look at the nodes allocated in the last section, we see
that their Next fields are currently NULL. Since the
link fields are type NodePointer, they can themselves be used to
designate values. The assignment statement
R.Next := P;
copies the value stored in P (an access value)
into the Next field of node R.ALL. In this way, nodes
R and P become connected. Similarly, the assignment
statement
P.Next := Q;
copies the access value stored in access variable
Q into the link field of node P.ALL, thereby
connecting nodes P and Q. The situation after
execution of these two assignment statements is shown in
Figure
14.6.
Figure 14.6
Connecting Nodes R.ALL, P.ALL and
Q.ALL
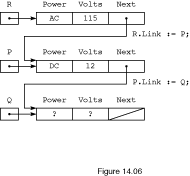
The data structure pointed to by R has now grown to form a chain
of all three nodes. The first node is referenced by R.ALL. The
second node can be referenced by P.ALL or R.Next.ALL
since they both have the same value. Finally, the third node may be referenced
by Q.ALL or P.Next.ALL or even
R.Next.Next.ALL.
Summary of Operations on Access Values
Let us summarize the operations available for access values. Access types are actually similar to private types. Given types
TYPE Something IS ... ;
TYPE PointerToSomething IS ACCESS Something;
if P1 and P2 are variables of type
PointerToSomething, and S is a variable of type
Something, the available operations are allocation, for
example,
P1 := NEW Something;
which allocates a block of type Something,
returning to P1 an access value designating the new block;
assignment, for example,
P2 := P1;
which copies the access value from P1 to
P2; dereferencing, for example,
S := P1.ALL;
which copies the value designated by P1 into
S; and equality/inequality, for example,
IF P1 = P2 THEN ...
which is True if and only if P1 and
P2 are equal. Be sure you understand the difference between the
line above and
IF P1.ALL = P2.ALL THEN ...
which compares the designated values.
You may be aware that in some other programming languages, especially C,
other operations, for example, incrementation and decrementation, are available
for pointer values. These operations are not available in Ada.
Returning Dynamic Storage to the Pool
In Figure 14.1 we allocated a block of storage from the pool but later caused its pointer to point elsewhere (see last two diagrams in Figure 14.1). Because no other access value designated it, the block became inaccessible. What happens to a inaccessible block?
In theory, the Ada storage allocator could include a module that automatically keeps track of inaccessible blocks and makes them available to be reallocated. Such a module is often called a garbage collector because it keeps track of discarded memory blocks. Garbage collectors are provided in some languages, especially Lisp and Snobol, but are very rarely included in Ada systems. This is because Ada was designed for use in real-time systems in which program timing is very important. Garbage collection is a complex process whose time performance can be unpredictable because it depends on how badly fragmented the storage pool is. For this reason, many Ada users prefer not to have a garbage collector and therefore compiler implementers usually do not provide it.
An Ada program that continually allocates blocks, then discards them just by
making them inaccessible, could well run out of pool storage at some point in
operation. Because an Ada system is unlikely to provide an automatic garbage
collector, the programmer is responsible for recycling the garbage. Luckily,
Ada provides a standard operation, Unchecked_Deallocation, to
return dynamically allocated storage to the pool. This is a generic procedure,
with the specification
GENERIC
TYPE Object IS LIMITED PRIVATE;
TYPE Name IS ACCESS Object;
PROCEDURE Unchecked_Deallocation (X: IN OUT Name);
To use this procedure, it must be WITH-ed in a
context clause, and instantiated using the access type and the designated type
as actual parameters. For example,
PROCEDURE Dispose IS
NEW Unchecked_Deallocation (Object => Node, Name => NodePointer);
creates an instance for the types used in this section, and the
procedure call statement
Dispose (X => P);
will return P's designated value to the pool.
Paraphrasing the Ada standard, we describe this operation as follows:
Dispose call, the value of P
is NULL.
P is already NULL, the call has no effect.
P is not NULL, then the call indicates that
P.ALL is no longer needed and may be returned to the pool.
Because we can copy access values, the situation can arise in which more
than one access value designates the same block of storage. For this reason, we
must be careful when returning storage to the pool. Errors will result if the
cells returned are later referenced by another access value that still
designates them; indeed, the Ada standard says specifically that the effect of
doing so is unpredictable. Suppose P designates a node. If we
write
Q := P;
Dispose(X => P);
then the cells designated by P are returned to the
pool and the meaning of Q.ALL or Q.Volts is
unpredictable. In this situation, a variable like Q is usually
called a dangling pointer. It is important to be sure that there is no
need for a particular record before returning the storage occupied by it. Also,
we must be careful when coding not to create dangling pointers; these lead to
execution errors that will not always give rise to nice Ada exceptions.
It is possible to exhaust the supply of cells in the pool. If this
happens in Ada, the storage allocator raises the predefined exception
Storage_Error.
Normally we can assume that there are enough memory cells available in the
pool. However, when writing large programs that create sizable dynamic data
structures, it is advisable to code an exception handler for
Storage_Error in the part of the program that does the allocation.
Later in the chapter we will discuss some methods for avoiding unnecessary
calls to the allocator.
a. R.Power := "CA";
b. P.ALL := R.ALL;
c. P.Power := "HT";
d. P := 54;
e. R.Link.Volts := 0;
f. P := R;
g. R.Link.Link.Power := "XY";
h. Q.Volts := R.Volts;
R := P;
P := Q;
Q := R;
are used to exchange the values of pointer variables
R and Q (type NodePointer). What do the
following assignment statements do?
R.Power := P.Power;
P.Power := Q.Power;
Q.Power := R.Power;
Copyright © 1996 by Addison-Wesley Publishing Company, Inc.